Go 并发与调试
本文是对Using the Go execution tracer to speed up fractal rendering这篇文章的翻译和整理。
作者源代码参见:Github
前言
本文中使用Go语言的版本为:1.9.2
本文使用代码来生成一张如下所示的图片:

初始代码
代码通过算法渲染图片上每一像素生成一张 2048x2048 大小的图片,代码如下:
package main
import (
"image"
"image/color"
"image/png"
"os"
)
const (
output = "output.png"
width = 2048
height = 2048
)
func norm(x, total int, min, max float64) float64 {
return (max-min)*float64(x)/float64(total) - max
}
func pixel(i, j, width, height int) color.Color {
// Play with this constant to increase the complexity of the fractal.
// In the justforfunc.com video this was set to 4.
const complexity = 1024
xi := norm(i, width, -1.0, 2)
yi := norm(j, height, -1, 1)
const maxI = 1000
x, y := 0., 0.
for i := 0; (x*x+y*y < complexity) && i < maxI; i++ {
x, y = x*x-y*y+xi, 2*x*y+yi
}
return color.Gray{uint8(x)}
}
func create(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
}
return m
}
func main() {
f, err := os.Create(output)
if err != nil {
panic(err)
}
img := create(width, height)
if err = png.Encode(f, img); err != nil {
panic(err)
}
}
在未进行任何优化情况下,这里通过create函数中双重循环来对每一像素进行计算它的颜色。
在本人电脑(Macbook Pro 2013)上运行时间为:
real 0m5.637s
user 0m5.575s
sys 0m0.037s
使用pprof进行分析
首先,使用Go标准库中pprof来对代码运行过程进行分析:
func main() {
pprof.StartCPUProfile(os.Stdout)
defer pprof.StopCPUProfile()
f, err := os.Create(output)
if err != nil {
panic(err)
}
// 使用WriteHeapProfile可以统计内存使用量
//pprof.WriteHeapProfile(os.Stdout)
}
首先,需要先引入runtime/pprof这个包,然后在main函数中引入两行即可。这里为了方便,直接将profile数据写入了标准输出中。
使用时候可以go run main.go > cpu.prof来定向写入到cpu.prof文件中。
再使用go tool pprof命令来对cpu.prof文件进行分析:
go tool pprof cpu.prof
这样就进入pprof交互式分析:
Type: cpu
Time: Nov 6, 2017 at 20:20pm (CST)
Duration: 5.83s, Total samples = 4.98s (85.39%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top -cum
Showing nodes accounting for 4.25s, 85.34% of 4.98s total
Dropped 28 nodes (cum <= 0.02s)
Showing top 10 nodes out of 46
flat flat% sum% cum cum%
0 0% 0% 4.80s 96.39% main.main /Users/allen/playground/golang/src/mandelbrot/main.go
0 0% 0% 4.80s 96.39% runtime.main /usr/local/opt/go/libexec/src/runtime/proc.go
0 0% 0% 4.37s 87.75% main.create /Users/allen/playground/golang/src/mandelbrot/main.go
3.23s 64.86% 64.86% 4.36s 87.55% main.pixel /Users/allen/playground/golang/src/mandelbrot/main.go
0.01s 0.2% 65.06% 1.12s 22.49% runtime.convT2Inoptr /usr/local/opt/go/libexec/src/runtime/iface.go
1.01s 20.28% 85.34% 1.11s 22.29% runtime.mallocgc /usr/local/opt/go/libexec/src/runtime/malloc.go
0 0% 85.34% 0.43s 8.63% image/png.(*Encoder).Encode /usr/local/opt/go/libexec/src/image/png/writer.go
0 0% 85.34% 0.43s 8.63% image/png.(*encoder).writeIDATs /usr/local/opt/go/libexec/src/image/png/writer.go
0 0% 85.34% 0.43s 8.63% image/png.(*encoder).writeImage /usr/local/opt/go/libexec/src/image/png/writer.go
0 0% 85.34% 0.43s 8.63% image/png.Encode /usr/local/opt/go/libexec/src/image/png/writer.go
(pprof) list main.main
Total: 4.98s
ROUTINE ======================== main.main in /Users/allen/playground/golang/src/mandelbrot/main.go
0 4.80s (flat, cum) 96.39% of Total
. . 49:
. . 50: f, err := os.Create(output)
. . 51: if err != nil {
. . 52: panic(err)
. . 53: }
. 4.37s 54: img := create(width, height)
. 430ms 55: if err = png.Encode(f, img); err != nil {
. . 56: panic(err)
. . 57: }
. . 58:}
(pprof) list main.create
Total: 4.98s
ROUTINE ======================== main.create in /Users/allen/playground/golang/src/mandelbrot/main.go
0 4.37s (flat, cum) 87.75% of Total
. . 34:
. . 35:func create(width, height int) image.Image {
. . 36: m := image.NewGray(image.Rect(0, 0, width, height))
. . 37: for i := 0; i < width; i++ {
. . 38: for j := 0; j < height; j++ {
. 4.37s 39: m.Set(i, j, pixel(i, j, width, height))
. . 40: }
. . 41: }
. . 42: return m
. . 43:}
. . 44:
这里通过top -cum以及list main.main和list main.create可以看到,主要时间都是用于m.Set这个方法。
主要原因是因为双重循环即O(n^2)级别时间都是调用了这个方法。
通过pprof统计内存使用可知,当前使用了 4MB 的内存空间
使用trace来查看执行过程
我们可以使用runtime/trace来查看程序运行过程。
import (
"runtime/trace"
)
func main() {
trace.Start(os.Stdout)
defer trace.Stop()
f, err := os.Create(output)
if err != nil {
panic(err)
}
}
将原来的pprof更改为trace即可。
重新运行程序:go run main.go > run.trace,这样会生成一个run.trace文件。
使用go tool trace run.trace即可运行一个查看运行过程的页面,它会自动在默认浏览器中打开。效果如下:
点击View trace即可看到运行追踪图:
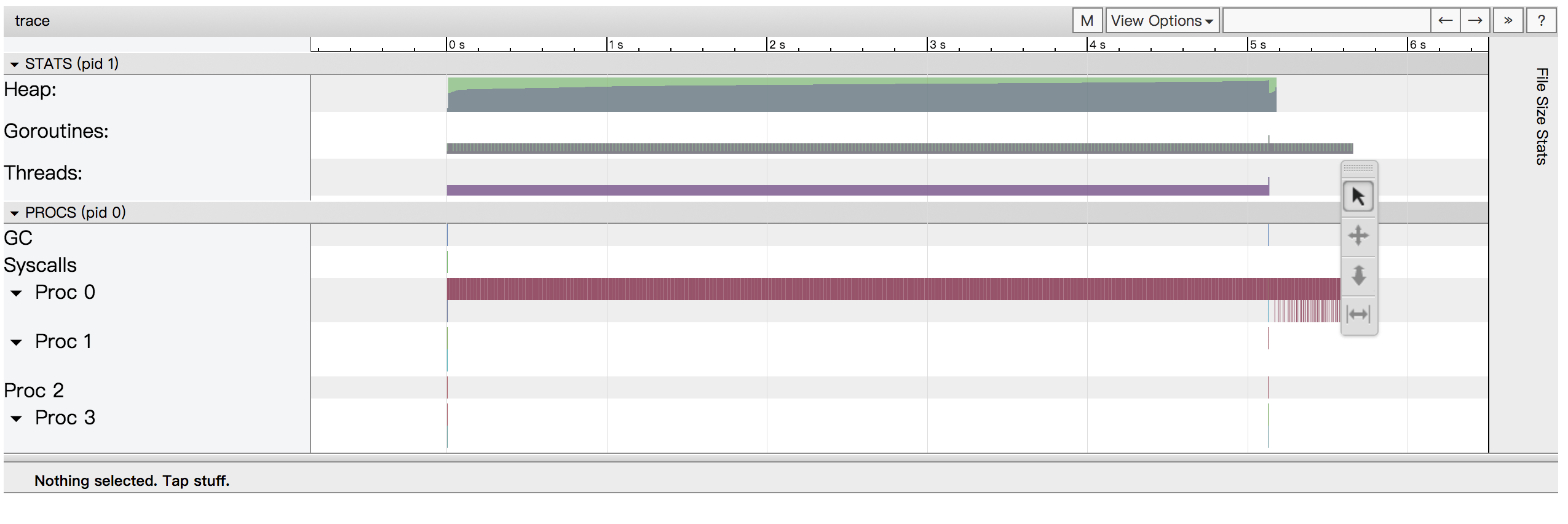
通过上图,可以看到,只有一个处理核心处于工作状态,其它处理核心处于空闲状态。这样并没有利用多核心处理器的优势, 也就是没有并行地执行程序。我们需要改造代码,使之能有效地利用多个核心来工作。
改造代码(一)
这里我们首先利用Go语言特性goroutine来进行并发处理。这里我们来改造一下create函数,如下所示:
func create(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
var wg sync.WaitGroup
wg.Add(width * height)
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
go func(i, j int) {
m.Set(i, j, pixel(i, j, width, height))
wg.Done()
}(i, j)
}
}
wg.Wait()
return m
}
再次执行,得到运行时间(这里运行前需要先注释掉trace代码,因为它会影响运行时间):
real 0m7.217s
user 0m18.043s
sys 0m2.314s
我们可以看到,执行时间甚至超过了不使用Goroutine的情况(当然,这里的时间在不同机器上会有不同,在某些核心数比较多的机器上会出现优于不使用Goroutine的情况)。
同样,我们使用go tool trace再来看一下具体运行情况。如下所示:

可以看到,出现了大量View trace的行。这是因为追踪数据量过大,为了便于使用,将其分割成很多块。
随便点击一行查看(载入数据可能需要一段时间…):
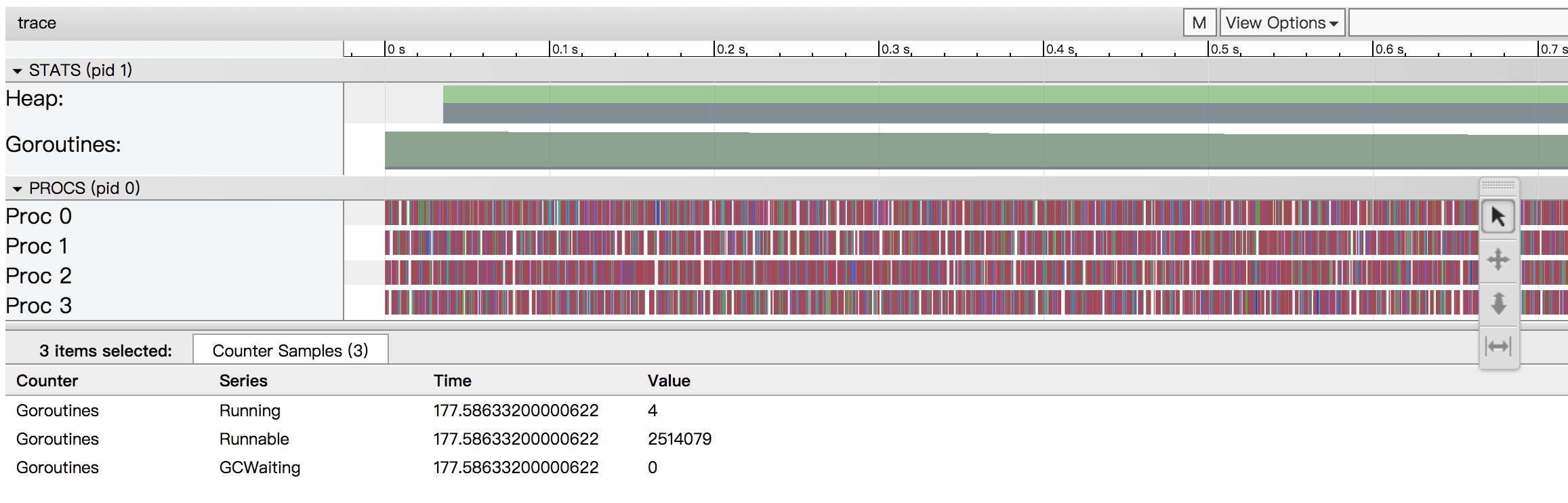
由上图可知,虽然我们创建了大量的Goroutine。但由于CPU物理限制,每时刻能运行的goroutine是有限的,大量的goroutine处于等待状态。而大量的goroutine对于Go运行时调度压力很大,而且GC压力也很大,大量时间花费于调度上。
通过pprof统计内存使用可知,当前使用了 400.65MB 的内存空间
使用race来查看并发竞争
在生成二进制执行文件时,可以使用-race选项来查看程序运行时竞争情况:
$ go build -o brot -race
$ time ./brot
race: limit on 8192 simultaneously alive goroutines is exceeded, dying
real 2m1.727s
user 2m14.872s
sys 0m41.609s
忽略掉上面的执行时间。可以看到,Go运行时最多支持8192个goroutine同时运行。而我们生成了四百多万(2048x2048)个goroutine。
同时,我们也可以使用benchmark来进行压测(具体细节请参考原文)。
综上可知,即使我们可以很轻易地创建上百万的goroutine,但最好不要这么做,有时候效果反而会适得其反。
改造代码(二)
由上可知,由于创建了大量的goroutine,所以反而得到不良的效果。这里我们可以尝试降低goroutine规模:
func create(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
var wg sync.WaitGroup
wg.Add(width)
for i := 0; i < width; i++ {
go func(i int) {
for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
wg.Done()
}(i)
}
wg.Wait()
return m
}
将原来每一像素一goroutine的方式改变为一列一个goroutine,减少goroutine数量到2048个。
可以得到运行时间为:
real 0m2.002s
user 0m6.212s
sys 0m0.029s
可以看到,程序运行时间从最初的5.6秒减少到了2秒。再次通过go tool trace来查看:
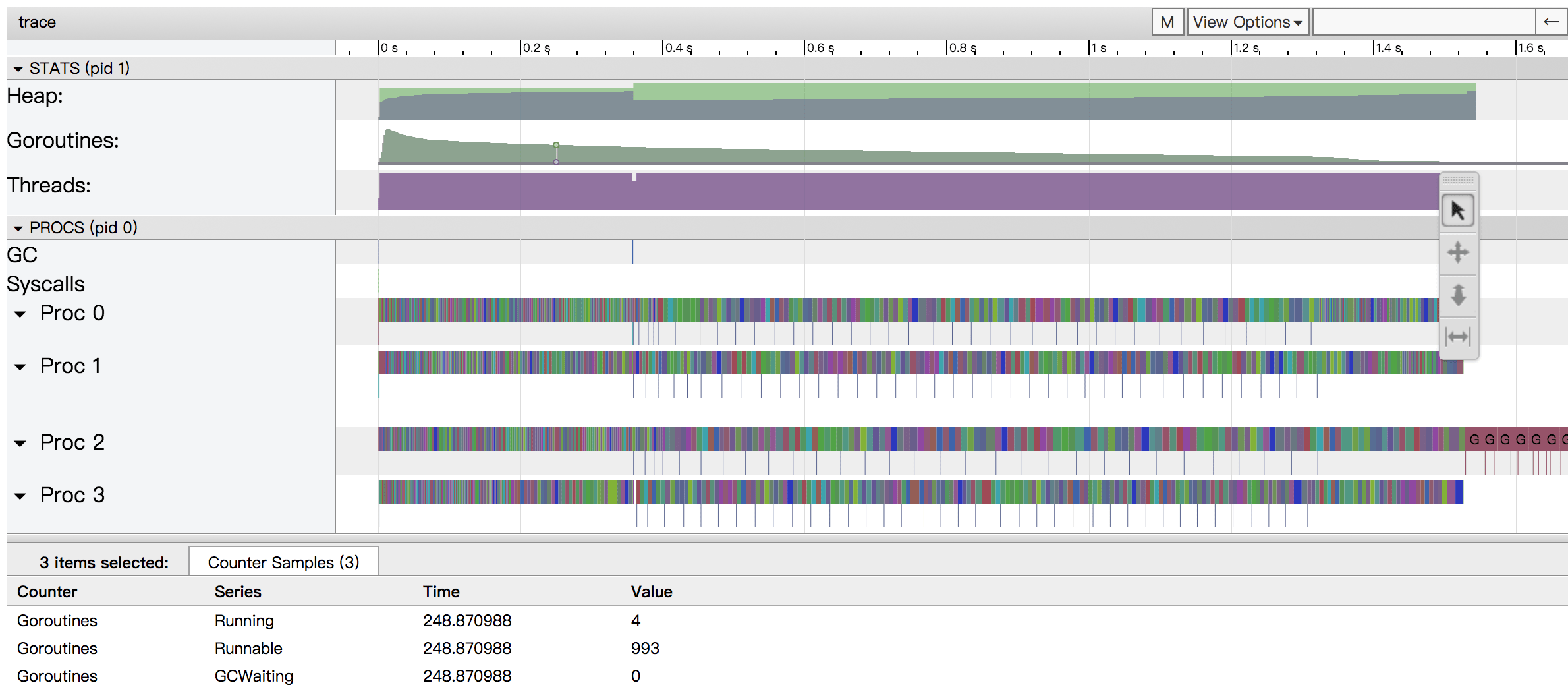
从上图可以看到,goroutine数量渐进降低。放大图可以看到,每个处理器都很连续地执行,没有了原来的调度压力。
通过pprof统计内存使用可知,当前使用了 4MB 的内存空间
改造代码(三)
上面代码直接采用goroutine来进行并发执行。在Go语言项目中,有很多使用 worker 模式来进行多任务执行。 即首先创建一定数量的worker,然后将任务分配给worker来执行。
func create(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
// 将worker数量设置为处理器核心数量
numWorkers := 4
// 创建一个新的包含每一像素点的结构体
type px struct{ x, y int }
// 创建一个分发channel
c := make(chan px)
var wg sync.WaitGroup
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ {
go func() {
for px := range c {
m.Set(px.x, px.y, pixel(px.x, px.y, width, height))
}
wg.Done()
}()
}
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
c <- px{i, j}
}
}
close(c)
wg.Wait()
return m
}
我们可以得到运行时间(time go run main.go)为:
real 0m4.766s
user 0m9.420s
sys 0m2.011s
虽然时间比最初的时间要短,但是要比按列的Goroutine方式要慢许多。
同样,我们使用go tool trace来查看一下,可以看到与前面每像素一个goroutine类似的trace图。
因为有大量的数据,所以被切分成了很多View trace行。
这里先不去看View trace,首先看一下Synchronization blocking profile如下所示:
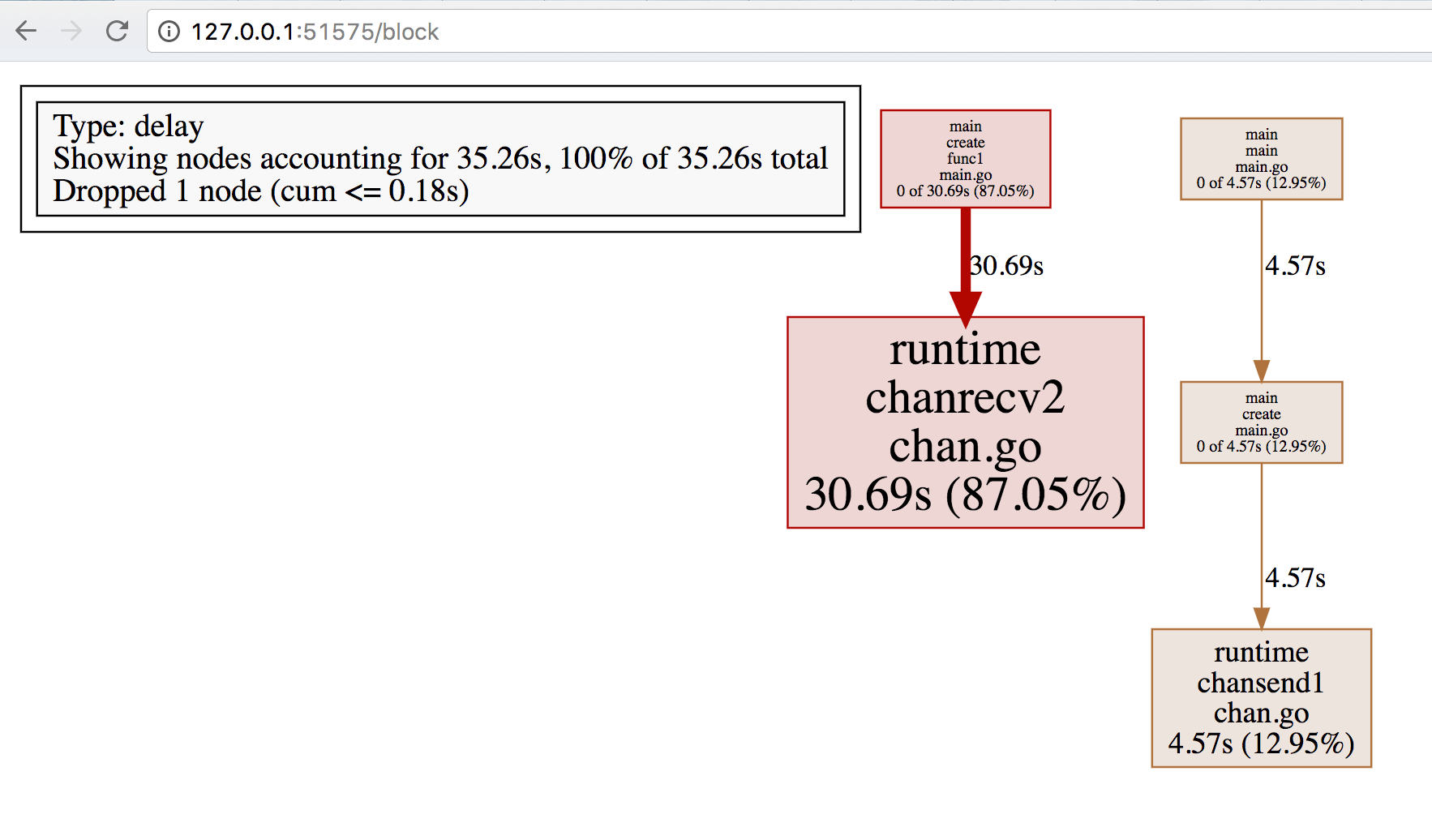
由上图可知,大量时间用于chansend和chanrecv,即用于发送和接收channel数据。
为什么会造成这样的情况呢?是由于上面代码中使用了阻塞channel(即channel中只能容纳一条数据)。
通过pprof统计内存使用可知,当前使用了 4MB 的内存空间
改造代码(四)
将上面的channel改造成为非阻塞channel来进行优化:
func create(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
// 将worker数量设置为处理器核心数量
numWorkers := 4
// 创建一个新的包含每一像素点的结构体
type px struct{ x, y int }
// 创建一个非阻塞分发channel,最大容纳量为所有像素数
c := make(chan px, width*height)
var wg sync.WaitGroup
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ {
go func() {
for px := range c {
m.Set(px.x, px.y, pixel(px.x, px.y, width, height))
}
wg.Done()
}()
}
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
c <- px{i, j}
}
}
close(c)
wg.Wait()
return m
}
得到程序运行时间:
real 0m2.964s
user 0m7.619s
sys 0m0.680s
接近于每列一个goroutine形式的性能。
通过pprof统计内存使用可知,当前使用了 68.01MB 的内存空间
改造代码(五)
上面使用worker方式代码,我们向channel中写入了四百多万次。即使写入开销很低,因为次数多了,也是有一定影响的。 这里我们可以按照前面goroutine优化方式,以每像素改为每列来进行优化:
func create(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
// 将worker数量设置为处理器核心数量
numWorkers := 4
// 创建一个分发channel
c := make(chan int)
var wg sync.WaitGroup
wg.Add(numWorkers)
for i := 0; i < numWorkers; i++ {
go func() {
for i := range c {
for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
}
wg.Done()
}()
}
for i := 0; i < width; i++ {
c <- i
}
close(c)
wg.Wait()
return m
}
得到程序运行时间:
real 0m2.095s
user 0m6.186s
sys 0m0.044s
可以看到,程序运行时间大致与每列一个goroutine方式相同。
同样,我们可以使用非阻塞channel来进行优化,程序运行时间为:
real 0m2.018s
user 0m6.214s
sys 0m0.037s
可以看到优化后会有一点改进,但是效果不明显。
通过pprof统计内存使用可知,当前使用了 4MB 的内存空间
总结
综上可知,每列一个goroutine方式似乎是最优的。但是,根据不同情况可能会有不同的结果。 因为虽然在Go语言中,创建一个goroutine的代价是很低的,但是始终还是有内存开销。 所以有时候使用worker方式,可能是最优的。具体情况还是需要根据实际场景进行判断选择。